
Breast Cancer Recurrence Risk Prediction with H‑Optimus‑1 and STAMP
Executive Summary
The Kather Lab, at Dresden University of Technology, is one of the leading computational pathology research teams worldwide. Their focus is on harnessing AI and computational modelling to extract actionable insights from routine clinical data, focusing on precision oncology and immunotherapy. Their goal is to build AI systems that combine multi‑modal data to discover new biomarkers and create decision-support tools for cancer care.
In a multi-institutional effort, led by medical student Gürcan Mustafa Özden at Goethe University Frankfurt, the team set out to design a system predicting breast cancer recurrence risk directly from biopsy whole-slide images (WSIs), reducing the need for costly and less accessible multigene assays. Their system uses a standardized end-to-end deep learning pipeline, called STAMP, combining a foundation model (FM) backbone with a downstream model to predict risk of recurrence from WSIs alone, classifying patients into high and non-high risk groups and evaluating downstream impact through survival analysis.
Results show that across both training and validation cohorts, H-Optimus-1 ranked among the top performers for binary classification of risk groups1. With further optimizations, this type of FM-based solution has the potential to be a key support tool for costly and low throughput clinical workflows and gene expression assays.
The Context: Making Recurrence Risk Assessment More Accessible
Breast cancer is the most common cancer worldwide and the leading cause of cancer‑related deaths in women. While current clinical practice classifies tumors by hormone receptors estrogen receptor (ER) and progesterone receptor (PR) and human epidermal growth factor receptor-2 (HER-2) status, this three‑marker system only partially captures the biological diversity of breast cancer. This is because breast cancer is a heterogeneous disease made up of various biologically distinct tumor types that behave very differently over time. Consequently, recurrent disease remains a central challenge in disease development.
Predicting breast cancer recurrence relies on identifying and quantifying biomarkers that reflect the underlying tumor biology. Beyond ER, PR, and HER2, gene expression analyses show that tumors can be grouped into four main “intrinsic” subtypes—Luminal A, Luminal B, HER2-enriched, and basal-like—which differ in hormone receptor status, response to therapy, and relapse patterns. Luminal A tumors are ER-positive with a relatively favorable prognosis but a long tail of late recurrences, Luminal B tumors are more proliferative and higher risk, basal-like tumors are triple-negative with early relapses, and HER2-enriched tumors historically had poor outcomes without HER2-targeted therapy. Across all of these groups, accurate risk stratification based on these molecular and clinical biomarkers is crucial for deciding whether to escalate or de-escalate adjuvant therapy, plan follow-up intensity, and counsel patients on long-term prognosis.
To meet this need, multigene assays and molecular tests have been developed to predict recurrence risk by integrating gene expression profiles with clinicopathologic features. These assays capture proliferation, signaling pathway activation, and other transcriptional programs associated with relapse, generating continuous risk scores that can be translated into clinically meaningful categories. These scores are classified into low, intermediate, and high risk strata, and then interpreted alongside traditional factors such as tumor size, nodal status, and grade. This combination of molecular and clinical information allows oncologists to identify patients who can safely avoid chemotherapy, those who clearly benefit from more intensive systemic treatment, and those in intermediate zones where individual factors and preferences guide the final treatment.
A reference multi-gene assay (MGA) for subtyping and risk of recurrence is PAM50. It measures the expression of 50 tumor‑related genes (plus reference genes) and uses this profile to assign a subtype and Risk of Recurrence Score (ROR‑S), by comparing the tumor’s expression pattern to reference expression signatures and integrating a proliferation index. The ROR-S is divided into predefined thresholds to create low‑, intermediate‑, and high‑risk categories. Low‑risk categories identify women with excellent outcomes on endocrine therapy alone, high‑risk categories flag patients who are more likely to benefit from chemotherapy or intensified systemic therapy, and intermediate scores sit in a gray zone where age, comorbidities, and other clinicopathologic features guide decision‑making.
The Challenge: Barriers for Multigene Assays
Multigene assays such as PAM50 have transformed how clinicians predict breast cancer recurrence risk, but their impact can be limited by key constraints: workflow access, complexity and cost.
From a workflow perspective, current MGAs like PAM50 rely on access to centralized labs, where samples require additional processing in preparation for the assays. This introduces extra turnaround time and logistical complexity, which many hospitals and healthcare systems cannot consistently absorb. As a result, even when these assays are technically available, clinicians often fall back on traditional clinico‑pathological variables and manual slide review, which are more subjective and less precise but easier to obtain at the point of care.
Furthermore, the cost of these assays remains another barrier. PAM50 and other MGAs require specialized platforms, validated laboratories, and robust quality systems, all of which add cost on top of standard histopathology. Even when a test is clinically indicated, reimbursement policies, patient co‑pays, and institutional budgets ultimately determine who is tested, while teams contend with operational overhead such as ordering kits, shipping specimens, tracking reports, and communicating complex results across language and literacy barriers.
Collectively, these constraints explain why PAM50‑based ROR‑S may be difficult to deploy at scale and why there is growing interest in simpler, more cost-effective approaches.
The Solution: Foundation Model–Powered Recurrence Risk Prediction
To overcome these challenges, the research team proposes a novel solution for predicting breast cancer recurrence risk using biopsy images (WSIs) alone. Their system uses a deep learning end-to-end pipeline called Solid Tumor Associative Modeling in Pathology (STAMP), which is a standardized, biomarker‑agnostic pipeline for predicting molecular biomarkers. In this setup, the STAMP pipeline is made up of a foundation model (FM) backbone performing feature extraction from the slides, followed by a downstream model acting as the slide-level predictor. The final output is patient stratification into groups of risk prediction (ROR‑High vs ROR‑Not High), and multiclass probabilities for several PAM50‑aligned risk categories.
Patients were included based on the following criteria for multigene prognostic testing: invasive breast cancer at Stage I, II, or IIIa with ER-positive, HER2-negative disease. The primary training cohort (MDX) consisted of 575 patients, of whom 246 were classified as ROR-High and 329 as ROR-Not High according to PAM50 ROR-S (risk of recurrence score). For external validation, the team used the TCGA-BRCA cohort of 448 patients, containing 173 ROR-High and 275 ROR-Not High cases. This two-cohort design enabled both internal cross-validation and out-of-cohort generalization testing.

The system was benchmarked through a 5-fold cross-validation method, using AUROC for binary classification (high vs non-high risk) and the following survival metrics: Kaplan–Meier curves, hazard ratios, C-index, and log-rank tests for progression-free survival. This dual evaluation framework ensured that models were judged not only on their ability to reproduce ROR-S labels but also on their capacity to stratify patients according to real clinical outcomes.
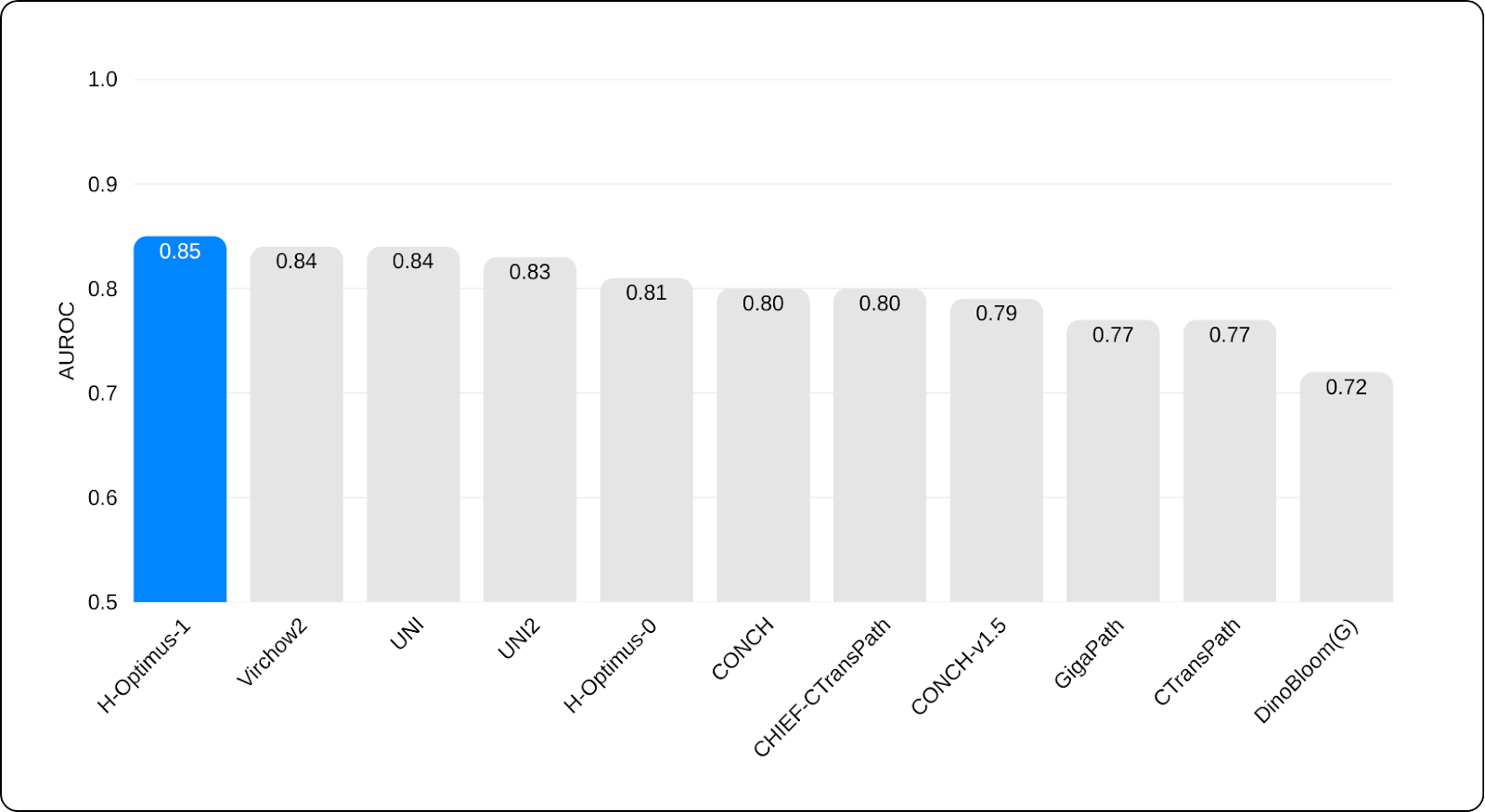
The team tested 11 state-of-the-art FMs, including H-Optimus-1, which emerged as one of the strongest backbones across both the internal and the external cohorts. On the validation, H-Optimus-1 achieved top place with an AUROC of 0.85. This indicates the system has the ability to classify patients by predicted risk, from the biopsy images alone. Furthermore, it also generalizes across datasets and institutions, a critical property for any model intended for real-world deployment.
Next, to understand whether these predictions translated into meaningful differences in patient outcomes, the team performed survival analyses focused on progression-free survival in the external cohort over a follow-up of up to 120 months. PAM50 ROR-S ranked at the top with a hazard ratio of (HR) 2.19, followed by H-optimus-1 in second place with a HR of 1.98. Kaplan–Meier analyses also revealed that patients classified as high-risk by PAM50 ROR-S had significantly worse progression-free survival than non-high-risk patients, with clear separation of the survival curves and statistical significance. High-risk groups defined by the FM-based system showed similar trends toward worse outcomes but did not reach statistical significance.
This suggests that while the proposed system performs well in risk label classification, it may require further optimizations to match the survival stratification performance achieved by PAM50. This could be explained by the STAMP framework, which is a backbone‑agnostic pipeline. By design, STAMP applies the same tiling strategy, feature aggregation scheme, and relatively simple slide‑level prediction head to all compared FMs, with limited hyperparameter and architecture tuning per backbone. This may constrain model expressivity and may underutilize the specific strengths of H‑Optimus‑1. As a result, there may be underestimation of the ceiling it could achieve compared to a task‑specific, fully optimized clinical pipeline.
The Impact: Towards Assay-Independent Recurrence Risk Prediction
The system proposed by the team highlights several important implications for how recurrence risk could be assessed in the future. By demonstrating that foundation models such as H‑Optimus‑1 have the potential to approximate ROR‑S directly from biopsy images alone, the team shows an alternative to MGAs.
1. Reduced diagnostic costs
The proposed FM-based system has the potential to act as a triage layer for multigene testing, helping clinicians decide which patients truly need additional molecular assays and which can be managed safely based on biopsy images analysis alone. In settings where budgets are constrained, this has clear implications for reducing per‑patient diagnostic costs, limiting expensive send‑out tests to the cases where they are most likely to change management. It also enables retrospective analysis of large slide archives that lack gene‑expression data, expanding the pool of patients who can benefit from recurrence‑risk insights without incurring new assay costs.
2. Simplified workflows for pathologists
Because the model operates directly on routine biopsy images, it fits into existing digital pathology workflows instead of adding another layer on top. Pathologists can obtain an FM‑derived recurrence‑risk signal before deciding to escalate analysis to PAM50 or other assays, so that these are only conducted when needed, rather than as a default.
3. Improvements in risk stratification and tailored treatment
This FM-based system offers a way to extend personalized treatment to more patients, in centers where multigene assays are underused or unavailable. Therefore, more women can be classified into correct low‑ and high‑risk groups, supporting chemotherapy de‑escalation for those with excellent prognoses and justifying intensified or prolonged systemic therapy for those at higher risk.
Conclusion
This work shows that H-Optimus-1, integrated with the STAMP pipeline, can classify breast cancer risk labels directly from biopsy images alone. Across both internal and external cohorts, H-Optimus-1 ranked as a top-performer among the 11 FM backbones evaluated. While H-Optimus-1 did not match the same performance as PAM50 in survival analyses, this gap could be explained by methodological constraints. The use of the standardized STAMP framework limits task specific optimization, potentially underutilizing the full representation capacity of H-Optimus-1. These results demonstrate that H-Optimus-1 has strong potential as a scalable and cost-effective decision-support tool, complementing existing molecular diagnostics to help bring personalized treatment to breast cancer patients worldwide.
Your Next Breakthrough
Bioptimus provides researchers and data scientists in pharma and biotech with the validated, state-of-the-art tools needed to turn ambitious goals into reality. If you are looking to power your research with a powerful, trusted foundation, the Bioptimus team is ready to support your work.
Contact us to learn how our models can accelerate your next project
About H-Optimus-1
H-Optimus-1 is a state-of-the-art foundation model for pathology developed by Bioptimus. It was trained using self-supervised learning on one of the most extensive and diverse datasets of its kind, comprising over 1 million pathology slides from more than 800,000 patients across thousands of clinical centers. This unprecedented patient diversity enables the model to learn a rich, generalizable understanding of human biology, allowing it to recognize a vast array of tissue patterns and disease signals. As a result, H-Optimus-1 has achieved state-of-the-art performance, outperforming other leading models across a wide range of industry-standard benchmarks, from predicting gene expression to identifying cancer metastasis.
About Bioptimus
Bioptimus is a global AI tech company that is pioneering the world's first universal foundation model for biology. By combining cutting-edge AI with massive multimodal, proprietary data generation, Bioptimus is building a unifying framework that connects all scales of biology, from molecules to patients in a framework that delivers interpretable, dynamic, and actionable insights. The first foundation model released by Bioptimus, H-Optimus, is an industry-leading model being adopted across research, drug discovery, and clinical pipelines.
References:
- Özden, G. M., Loeffler, C. M. L., Paul, E. D., Ferjentsik, Z., Hrabovska, S., Nemeth, F., Vereš, I., Cekan, P., & Kather, J. N. End-to-End Deep Learning for Predicting Breast Cancer Recurrence Risk. Poster