
MIT partners with Bioptimus for Clinical Cancer Prediction Study
Executive Summary
MIT researchers, led by renowned Professor Regina Barzilay, conducted a direct comparison of a curated set of publicly available pathology models1 to select the best tool for their work on ARPA-H ADAPT, a landmark U.S. government initiative designed to transform cancer treatment (pending publication).
The team's goal was to identify the model with the highest accuracy for predicting Progression-Free Survival (PFS). In this competitive evaluation, H-Optimus-1 emerged decisively as the top-performing model [1,2].
This case study details the benchmark and outlines metrics around H-Optimus-1 predictive power, which is accelerating MIT’s progress in one of the nation's most ambitious cancer research initiatives.
1. H-Optimus-0, H-Optimus-1, UNI2, CTranspath/Chief, and Virchow.
The Challenge: Building a reliable predictive engine for the ADAPT’s complex biological foundation
The ADAPT program's mission is to revolutionize care for patients with metastatic breast, lung, and colon cancer by developing tools that can anticipate a tumor's evolution and guide therapy choices at the bedside. The main goal is to be able to look at a patient's tumor today and get a real sense of what it will do tomorrow.
For the MIT team contributing to this initiative, the core of the problem lay in the data itself. A single pathology slide contains a universe of information; its resolution is so high that you can see each individual cell, cancerous and non-cancerous alike. Hidden within this avalanche of information is the faint but crucial "signal" that can predict a patient's outcome.
To find it, the team needed a tool capable of learning from the complexity of biology at an unprecedented scale, yet flexible enough to be adapted to specific clinical questions like predicting PFS. The team knew that committing to the wrong approach would mean months of wasted resources, critical delays, and a high risk of project failure.
The central challenge was clear: how do you build a reliable, predictive engine on such a complex and vast biological foundation?
The Context: A new class of AI for Biology
The MIT team, with its extensive experience in Clinical AI and Radiology, understood that building a predictive model from scratch for a problem of this magnitude was impractical. The traditional approach would require a massive, task-specific dataset, vast supercomputing power, and years of development time they didn't have.
Instead, they turned to today’s increasingly common paradigm: leveraging a pre-trained foundation model.
Unlike traditional models built from scratch for a single task, a foundation model is first pre-trained on a massive, diverse dataset. This gives the model a deep, general-purpose understanding of a domain; in this case, the visual language of human biology. This pre-trained foundation can then be efficiently adapted to solve numerous specific problems.
For the team focused on the clinical mission, this meant they needed to start with a model that had already learned the fundamentals of histology to significantly accelerate their work.
The Solution: Using H-Optimus-1 for state-of-the-art predictive precision
To resolve their challenge, the MIT team conducted a rigorous head-to-head benchmark of publicly available pathology foundation models. The goal was simple: which foundation model provides the most accurate predictions for PFS from baseline tumor pathology slide images?
Their methodology was straightforward:
- Data: The team used pathology slides from The Cancer Genome Atlas (TCGA), one of the largest public datasets of histopathology slides
- Task: For each model, they took digitized pathology slides, and transformed them through the foundation models to generate embeddings (feature rich representations). The survival prediction model was developed as an overlay of these embeddings. Each model was given the same mission: analyze the slides and extract the key biological features (a signature) that could predict Progression-Free Survival (PFS), the program’s target clinical endpoint
- Evaluation: Finally, the embeddings extracted by each model were used to see which feature set could most accurately provide a signature for predicting patient outcomes

The results of this competitive evaluation were definitive. The features extracted by H-Optimus-1 yielded consistently more accurate predictions than any of the other models tested. H-Optimus-1 is now the validated, top-performing engine chosen to power MIT's mission-critical work for the ARPA-H ADAPT program.
The Impact: This Top-Performing Model Provides a Strategic Advantage
Using H-Optimus-1 doesn't just give the MIT team a superior predictive score, it provides three strategic advantages that directly impact the speed and success in the race to better stratify patients.
Dr. Barzilay added, “It was important to us that we could see strong performance on a well characterised dataset such as TCGA, especially with models which were not trained on that data. This gives us more confidence that the model will generalise in new settings. We were very pleased with the strong performance and utility of H-Optimus-1.”
1. Enabling Faster Clinical Insights
The model shows exceptional strength in short-term predictions, 6-month progression free survival (PFS), as one example. When applied in a clinical trial setting, H-Optimus-1 may provide an early signal, indicating whether a patient is likely to progress rapidly. The hope is that this increased prognostic power will enable more confident treatment decisions and better trial designs—in turn saving millions in R&D costs by providing better precision in patient treatment plans.
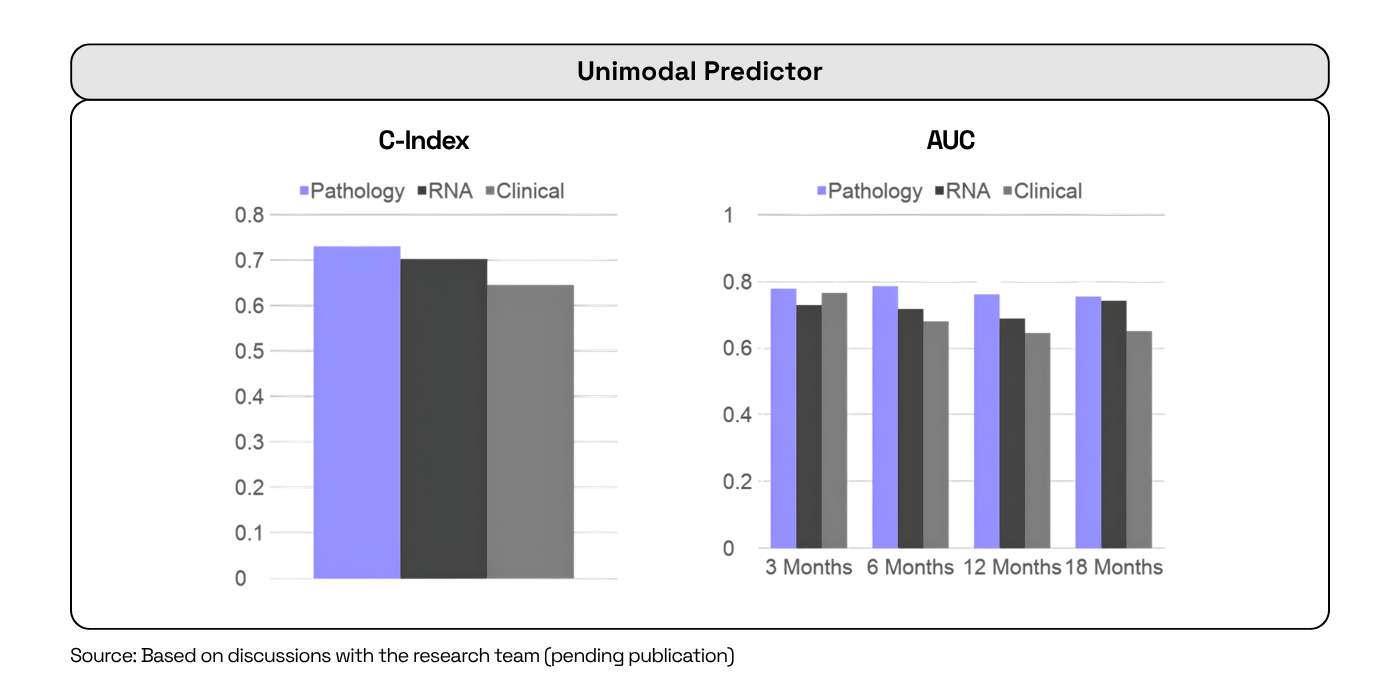
Observed results: H-Optimus-1 demonstrates exceptional utility for near-term predictions, with a consistent C-index (a measure of model discrimination) and >0.75 AUC using H-Optimus-1 for 6 month PFS, and approaching 0.75 for 12 and 18 month PFS endpoints.
2. Building a Deeper Biological Picture
The MIT team also used H-Optimus-1's analysis as the visual foundation for a more complex multimodal model, combining it with genomic data (RNA-seq). This fusion enhanced the model's predictive power, proving that H-Optimus-1 provides a high-fidelity signal that can be integrated with other data sources. This is key for discovering more robust signatures and developing a more complete understanding of disease.
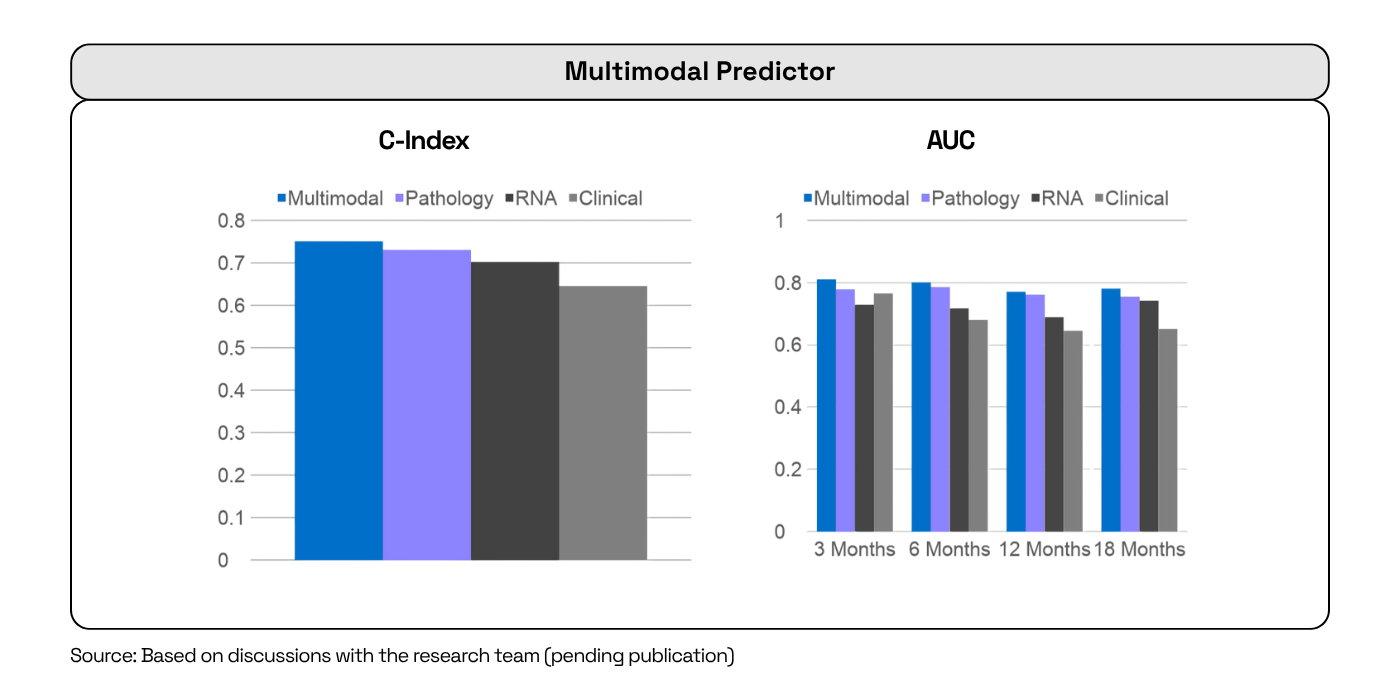
Observed results: H-Optimus-1 leads to a visible improvement in predictive power, achieving a C-index in the 0.75-0.76 range and time-dependent AUCs close to 0.8 across different time stamps.
"When a model reaches around 0.8 AUC for six-month predictions, you’re getting close to something that can really matter in a clinical setting. That’s where it becomes exciting — when solid performance begins to translate into insights that can truly guide patient care.", added Ayed.
3. Accelerating the Path to Clinic
By delivering a decisive win in the initial benchmark, H-Optimus-1 saved the MIT team months of foundational work, enabling them to move beyond further testing of other models. This acceleration is a powerful competitive advantage, allowing research teams to move faster from the lab to clinical trials, where true clinical impact can be determined.
Conclusion: The Strategic Value of Starting with H-Optimus-1
The MIT team's experience in the ARPA-H ADAPT program demonstrates a critical lesson for any organization in the life sciences: the choice of a foundational model is not just a technical detail, it's a strategic decision that dictates the pace and potential of your entire research project.
By selecting the top-performing model from the outset, the team secured a powerful advantage: accelerating their timeline, enabling deeper insights, and de-risking their path to the clinic.
Your Next Breakthrough
Bioptimus provides researchers and data scientists in pharma and biotech with the validated, state-of-the-art tools needed to turn ambitious goals into reality. If you are looking to power your research with a powerful, trusted foundation, the Bioptimus team is ready to support your work.
Contact us to learn how our models can accelerate your next project
About H-Optimus-1
H-Optimus-1 is a state-of-the-art foundation model for pathology developed by Bioptimus. It was trained using self-supervised learning on one of the most extensive and diverse datasets of its kind, comprising over 1 million pathology slides from more than 800,000 patients across thousands of clinical centers. This unprecedented patient diversity enables the model to learn a rich, generalizable understanding of human biology, allowing it to recognize a vast array of tissue patterns and disease signals. As a result, H-Optimus-1 has achieved state-of-the-art performance, outperforming other leading models across a wide range of industry-standard benchmarks, from predicting gene expression to identifying cancer metastasis.
About Bioptimus
Bioptimus is a global AI tech company that is pioneering the world's first universal foundation model for biology. By combining cutting-edge AI with massive multimodal, proprietary data generation, Bioptimus is building a unifying framework that connects all scales of biology, from molecules to patients in a framework that delivers interpretable, dynamic, and actionable insights. The first foundation model released by Bioptimus, H-Optimus, is an industry-leading model being adopted across research, drug discovery, and clinical pipelines.
References:
- Jaume, G., Doucet, P., Song, A. H., Lu, M. Y., Almagro-Perez, C., Wagner, S. J., Vaidya, A. J., Chen, R. J., Williamson, D. F. K., Kim, A., & Mahmood, F. HEST-1k: A Dataset for Spatial Transcriptomics and Histology Image Analysis. Advances in Neural Information Processing Systems, December 2024
- PathBench